Every few years, I’ve posted a chart of which modes are being used on the air (based on what is uploaded to Club Log). This report isn’t lightweight to calculate, so I don’t have it as a standard feature in Club Log for you to access, but I’m just as interested in the results as everyone else. 2017 was, of course, the year when digital modes changed forever with the advent of FT8. It is a remarkable technical achievement which has breathed life and enthusiasm into DXing for a whole new audience. See what you think about the side-effects.
Modes used during 2017 – and the arrival of FT8
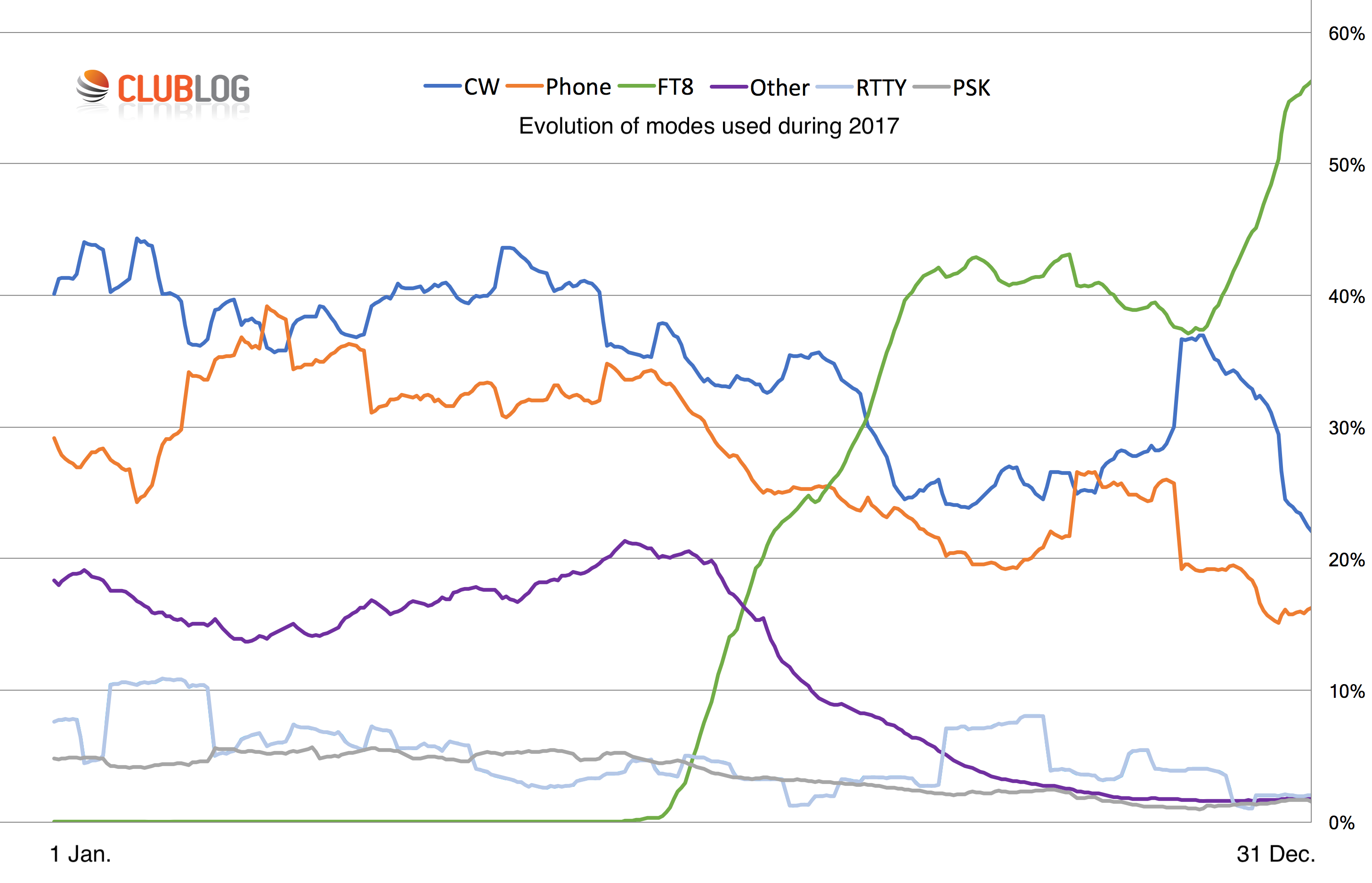
Club Log graph showing modes used by radio amateurs in 2017, and the emergence of the FT8 digital mode
Other statistics:
8,000 Club Log users uploaded FT8 QSOs in 2017, and they logged a total of 46,000 distinct callsigns in that mode. For reference, in 2017 the total number of QSOs uploaded to Club Log (all modes) was 32 million. Of that total, the number of QSOs made with FT8 was 4.8 million.
Note on data smoothing:
The lines are based on 28-day moving averages. I applied this smoothing to reduce the prominence of peaks related to mode-specific contests, such as CQWW SSB and CW.
Note to editors and news outlets:
You may reproduce the graph without asking for permission, provided it is not modified, and is attributed to Club Log (e.g. “Credit: clublog.org”). Click on the chart to download the underlying image.
Don’t forget to read Gary, ZL2iFB’s guide to FT8 and his comments on the culture of the mode. It is a really useful PDF which will help any new user of the mode: http://www.physics.princeton.edu/pulsar/K1JT/FT8_Operating_Tips.pdf
Hi Gary, do you have a set for each band, or can the data be separated out that way? I’d be interested in a 10m graph.
Cheers
Tony G4CJC
Thanks for that Michael it makes interesting reading, and backs up my thoughts and experiences over the last year.
I suspect it will change again as propagation starts to improve.
I must say it’s interesting to work JA’s nearly every morning at up to -24db/A when the bands appear flat.
Take care and many thanks.
I wouldn’t begin to know how to calculate it, but there is probably some data-collection bias in that digital mode users are more likely to upload their logs (which are, of course, digital) than are others.
That said, I wonder how large the new group of DXers is, ie how many FT8 users have not uploaded logs before.
Thank you Michael, interesting to see that as FT8 took off, CW dropped as a mirror image.
Its great data. However the title is completely misleading. The assumption is that the same proportion of “on the air” activity is equal to the Clublog uploads. I have a VERY competitive station and listen on the bands ALOT. The evidence of actual on the air activity is not consistent with your graphs. Lets see how the % break out after the 3Y0 DXpedition as to Qs and calls in the logs.
Ed N1UR
Thanks Michael! Fascinating data: I believe this is more than just a passing fad, with implications going forward that are not entirely clear at this point. Meanwhile, while FT8 delivers me a sizeable volume of QSOs, CW is still the best for quality and fun (for me)!
I see that G3TXF was spotted yesterday using FT8. Now there’s a turn up for the books.
Hi Ed –
Data in Club Log is generally statistically significant enough to draw conclusions. For example, the most wanted list can be generated from 500 million QSOs or from 50 million QSOs, and produces the same result. These graphs are not likely to radically change shape if more logs are added at this stage; I’m speaking from experience on dealing with this data set.
I would also have to say that I *have* heard this trend on the air: plenty of bands with nothing at all going on except FT8. Also, calling CQ on an open band in CW or (harder still) on SSB, and getting no response.
As you rightly say, the coming year will be extremely interesting. FT8 has had a spectacular beginning and it’s hard to know what might happen next – or whether it will still be quite so popular when conditions change. I’ll keep running the reports based on the evidence in the uploaded logs, and we can collectively try our best to interpret that.
73
Michael G7VJR
Great statistics. Would be interesting to know how many DXCC entities have been active in FT8.
There is a significant bias here which needs to be considered, FT8 users are far more likely to upload their logs to the Internet than users of SSB (and possibly other modes).
Evidence: I upload all of my logs to LoTW and use that to update my qrz.com log.
About 85% of my FT8 QSOs get confirmed
About 25% of my SSB QSOs get confirmed
I think it’s reasonable to suppose many if not most FT8 users are chasing awards, there’s not a huge amount of pleasure to using the mode beyond the fun of snagging a new DXCC entity.
Whereas on SSB, many people are just interested in rag-chews or at least are not interested in electronically confirming QSOs, and these do actually represent the majority using SSB.
Interesting discussion here. I’d like to point out one thing: The graph shows relative mode useage over time. This may not be interpreted like “Overall CW usage dropped in favor of FT8.” Absolute data (# of QSOs) over time would be more interesting.
For me, FT8 is a nice hobby. But modes where the OP skills count (CW especially) are more than that, these are my passion. RTTY requires knowledge and skills, while FT8 is somehow a fool-proof mode. It changes the whole game in regards of DXCC in DATA mode. I think it is a great mode for DX beginners, or those with limited antenna possibilities (including myself).
Jan – this is a very good point. When I checked the raw data, however, I found that absolute usage of other modes *did* drop. I think many operators have biased their time in the shack to FT8.
Thanks Michael for clarifying this point!
So, we can conclude from what you and Phil pointed out:
At least OPs who frequently upload their data to clublog have migrated to FT8 from other modes by a significant amount.
Let’s see how long the hype will last, IF it is just a hype…
Hi!
Fits my experience. I do much less CW now.
One point on “other” modes.
JT65/JT9(JT10) used on HF (not EME) are predecesors of FT8,
while MSK144, AX.25 are real “other mode”.
With FT8 storm, JT65 become rare on HF (I checked few times on 160m, never heard a DX there). Is the impact to other “other” modes same?
If raw data is still around, maybe separate pre-FT8 and other other modes might give some insight?
TNX, best 73
Iztok, s52d
Pingback: Evaluación del uso de los modos: 2017 fue “el año en que los modos digitales cambiaron para siempre”. – Puerto Rico Amateur Radio League
Am I reading the graph correctly?
i.e, by Dec 31st the QSOs in the logs uploaded in the last 28days averaged ~55% FT8, ~22% CW; 15% Ph and the rest RTTY+PSK?
I think it’s both, change and hype.
From my DXers point of view: CW, or RTTY too, are much more fun than FT8. But there are some important points why I think it’s partially a hype:
– I have a lot of digital mode slots to fill –> FT8 is useful for people such as me right now. Now. Not any more, if I have closed most white gaps.
– There has not been much DX on the air in december –> Much time left for FT8.
– FT8 is all-new. Chance to do something new. One day, it will not be new any more, and world is “coming back to normal”
But, of course:
– FT8 allows me to run my station while doing other things. I win time.
– FT8 allows me to do qsos when none of my preferred modes works, especially worthful at my main QTH where I have small antennas only.
Summarized, I see FT8 not only as a hype, but it will not completely replace “manual” modes. Due to the high degree of standardization of message content, especially it will never be useful for ragchewing etc.
AND: CW & SSB pileups, even well-handled RTTY pileups, are much faster.
My guess: FT8 has a certain chance to replace perhaps 20% of non-contesting activity in other modes, and to add some 10-20% extra activity.
Absolute figures would be much appreciated!
Pingback: 2017 was “the Year When Digital Modes Changed Forever” – The Radio Amateur Society of Australia
A technology which can do what FT8 does is definitely a great resource for learning more about propagation, noise floor, etc… At this stage DXing with it is about as demanding as shooting fish in a barrel. It takes practically no skill to make contacts with a modulation mode that can detect a signal which is nearly 30 dBm below the noise floor. Why not just use the Internet to do your DXing? That said, please don’t conclude that I dislike the technology or the fact that people are using it. Help yourself and by all means enjoy yourself. As for me and my house we will continue our love affair with QRP CW. W4MHZ
Pingback: FT8: New stats, new operating guide - KB6NU's Ham Radio Blog